Penalty Estimation And Violation Detection
Swati Kanwal, Pulkit Parikh, Kamal Karlapalem
We propose to use a two step approach that leverages machine learning based methods to first, semantically segment legal text into eleven legally relevant categories by training a multi-class classifier. And then, train models to perform specialized tasks like penalty estimation and violation detection based on semantically relevant information required for each of the specialized tasks.
Step1: Semantic Segmentation
Eleven labels are defined for sentence level semantic segmentation of legal text, namely, procedural fact, material fact, related fact, statutory fact, related fact, issues framed, allegation, defendant claim, violation, penalty, subjective observation and others. Sentence level annotations of adjudication orders from the SEBI website serve as training data for the sentence classifier. This labelling is used to improve the efficiency of annotation and dataset creation to facilitate tasks like penalty estimation and violation detection.
Label Definitions:
- Facts (Material) – Statements that contain information about the case that is relevant and important in deciding the outcome as well as the violation and penalty, if any.
- Facts (Procedural) – Statements that contain generic information on the procedure duly followed by the authorities to set the process of adjudication in motion.
- Statutory Facts – Statements that invoke rules, regulations, acts and orders by the SEBI, either by using their representative names and numbers or by quoting them in totality.
- Related Facts – Statements made in a general sense, including truisms, reemphasis of statutory facts which do not constitute the facts of the instant case, but are material in deciding its outcome.
- Issues Framed – Statements that are in the form of questions, that are the principal questions of law or fact that need to be adjudicated upon.
- Subjective Observation – Statements that are based on the personal feeling or conclusion of the adjudicating officer or tribunal member, based on their reading of the facts and defendant claims.
- Defendant Claims – Statements that elaborate the stand taken by a defendant/accused by way of countering or accepting, or partially countering or partially accepting the accusations/allegations made on him.
- Allegation – Statements that accuse individuals or entities of violating a regulation or a set of regulations, based on the understanding of facts by SEBI.
- Penalty – Statements that talk about the monetary penalty that should or should not be imposed, including the reason given therein by way of the regulation violated.
- Violation – Statements that conclusively talk about the violation of a particular regulation or a set of regulations, acts and rules.
Step 2: Specialized tasks
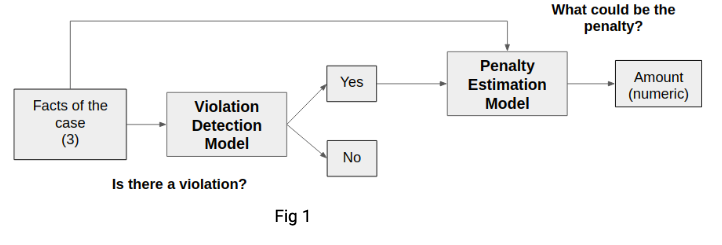
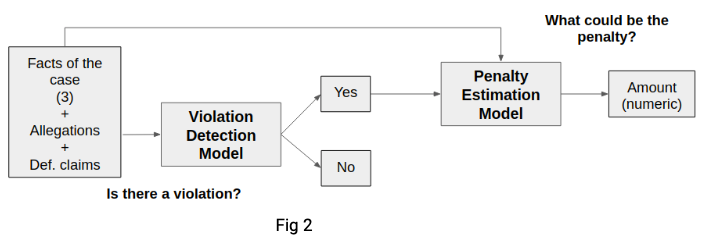
There are two main use cases that the final model aims to handle, the first is the Automated Legal Advice use case (Fig. 1) and the second is the Automated Legal Judgment use case (Fig. 2). Essentially, the only difference between these two use cases is the input that it considers for making an evaluation. In the first use case, only facts of the case are used to estimate the violation and the penalty whereas in the second use case facts along with allegations and defendant's claims are used to make the judgement. Automated Legal Advice use case takes into account the point of view of a lawyer or a legal advisor whereas the Automated Legal Judgment use case makes a decision from the point of view of a judge or an adjudicating officer.
Data: HERE
DEMO: HERE